。任務多樣且相互耦合,導致空天智能體的任務定義至今仍不清晰
。
無人機3D數(shù)據(jù)采集難:采集戶外環(huán)境3D數(shù)據(jù)需要無人機等設備,門檻較高,并且戶外3D數(shù)據(jù)采集需要專業(yè)人員操控無人機在更廣的范圍中采集更多的點云數(shù)據(jù)。
無人機具身數(shù)據(jù)標注成本高:無人機智能體的動作空間多,需要對標注人員進行長期的培訓才能完成對無人機智能體的熟練標注。

空天具身智能領域的應用主要包括以下方面:
無人機自主導航與控制:提高無人機在復雜城市環(huán)境中的自主導航 、避障和任務執(zhí)行能力。
衛(wèi)星遙感與智能解析:空天具身智能技術可應用于衛(wèi)星遙感圖像的智能解析 ,提高衛(wèi)星對地觀測數(shù)據(jù)的處理和分析能力
。
空中交通管理:利用無人機具身智能技術 ,實現(xiàn)空中交通的自主管理,提高空中交通系統(tǒng)的安全性和效率
。
災害監(jiān)測與救援:無人機智能體可應用于災害現(xiàn)場的快速偵查 、監(jiān)測和救援任務,提高救援效率
。
城市規(guī)劃與管理:通過無人機智能體收集的城市空間數(shù)據(jù) ,為城市規(guī)劃、建設和管理工作提供有力支持
。
環(huán)境保護與監(jiān)測:利用無人機智能體對環(huán)境進行實時監(jiān)測 ,及時發(fā)現(xiàn)和處理環(huán)境污染問題。
軍事領域:空天具身智能技術可應用于軍事偵察 、目標識別
、戰(zhàn)場態(tài)勢感知等方面,提高軍事作戰(zhàn)能力
SkyAgent-Models:空天智能體模型
空天具身場景感知:二維視覺語言模型的視覺模型僅能接收圖片 ,無法接收環(huán)境特征
,因此在測試該任務時對二維視覺語言模型進行調(diào)整,將輸入改為無人機位置前后左右所拍攝的四張圖片
,通過描述圖片的
prompt生成各自的caption之后 ,對四個caption進行拼接,得到輸出的環(huán)境觀察信息
。
空天具身空間推理:該任務同樣需要輸入三維特征 ,因此在測試該任務時對二維視覺語言模型進行調(diào)整,將輸入改為無人機位置正前方的觀察圖像與問題
,通過對該圖像進行推理問答
,得到空間推理答案。
空天具身導航探索:將輸入改為無人機飛行路徑上的幾張圖片和問題,通過生成各自圖像的caption之后,根據(jù)拼接后的caption回答問題,最終得到無人機導航探索的答案。
空天具身任務規(guī)劃:首先通過對終點圖片生成caption并設計問題,即詢問無人機智能體怎么到達該地點。然后,依據(jù)拼接后的飛行路徑圖片caption進行解答,得到無人機路徑規(guī)劃的答案。

易和聯(lián)航&具身智能體AIBOX

公司愿景:
以通信、定位、導航、識別、控制(CLNRC)五大智能體核心能力為技術底座,通過具身智能理論構(gòu)建智能體物理存在與數(shù)字認知的深度融合,讓智能系統(tǒng)不僅擁有環(huán)境感知的大腦,更具備與環(huán)境共融的"身體"。結(jié)合人工智能與自動駕駛技術的深度耦合,打造具有物理具身性、環(huán)境交互性和認知涌現(xiàn)性的跨設備(無人機/機械臂/機器狗/無人艇)、跨介質(zhì)(陸地/空中/水域)、跨場景的自主決策系統(tǒng),致力于成為無人化垂直場景的智能基礎設施構(gòu)建者。
讓智能體突破人類操作的物理邊疆
通過構(gòu)建空間智能時代的具身智能載體:"手"(機械臂)、"足"(機器狗)、"翼"(無人機) 、"鰭"(無人艇)
,我們正在重新定義生產(chǎn)力工具的邊界。每個智能體通過多模態(tài)
傳感器形成"數(shù)字軀體"
,在真實物理環(huán)境中實現(xiàn)感知-決策-執(zhí)行的具身閉環(huán)
,讓危險場景無人值守,讓精密操作無限重復
,讓人類專注更具創(chuàng)造力的價值領域
。
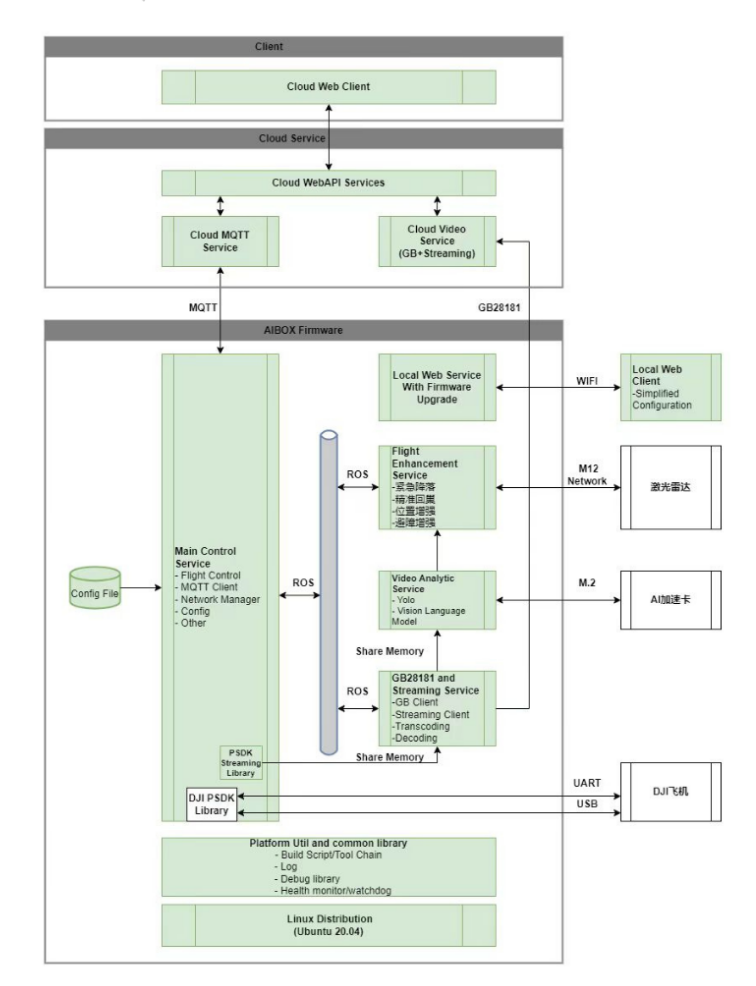
核心技術與產(chǎn)品布局
公司聚焦定位、導航、邊緣視覺大模型等核心技術,推出AiBox系列產(chǎn)品,涵蓋通信增強、安全增強、算力增強等功能,滿足不同無人化場景需求。









